Logbuch in der Cloud
Wie können wir Azure-Dienste sinnvoll und sicher in Nicht-Cloud-Applikationen einsetzen?

Ich zeige anhand von Beispielen aus meinem Projektalltag verschiedene Szenarien, in denen Cloud-Dienste eine Lösung für gängige Probleme lokaler Applikationen bieten. In diesem Beitrag geht es um das clientseitige Logging und darum, wie wir die Azure-Infrastruktur hierfür nutzen können.

Müde Augen ade: So helfen kurze Codezeilen

«Die Digitalisierung scheitert, wenn sie dem Menschen die Autonomie nimmt»

«Der richtige KI-Hype steht erst noch bevor»

HR-Digitalisierung auf den Menschen ausgerichtet
Ziel dieser Serie ist, dass Sie die Möglichkeiten der Azure- Dienste für Ihre eigenen Applikationen erkennen und deren Konzept verstehen. Ich begleite die fünf Artikel auf meinem Blog, wo Sie weitere Informationen zum Thema und eine Visual-Studio-Solution zur Demonstration der Lösung finden [1] .
Das Problem
Um das Problem des clientseitigen Loggings zu erklären, nehmen wir als Beispiel eine klassische Client-/ Serverarchitektur mit einem WPF-Client und einem Web-API-Server. Sowohl auf der Server- als auch auf der Clientseite interessieren wir uns für bestimmte Laufzeitinformationen. Das können z. B. aufgetretene Fehler sein, die wir protokollieren möchten, um sie im nächsten Release zu beheben. Möglich sind aber auch Monitoring-Informationen wie Performance-Messungen von Abfragen oder Tracking-Daten des Benutzerverhaltens zu Audit- oder Optimierungszwecken. Im Idealfall loggen wir, um zu erkennen, ob sich unser System so verhält, wie von uns erwartet.
Auf der Serverseite ist Logging in der Regel kein Problem. Wir verwenden dafür eine Library, die uns einen Großteil der Arbeit abnimmt. Spezielle Tools ermöglichen uns eine rasche Auswertung der protokollierten Informationen. Eine Liste geeigneter Logging Libraries für .NET finden Sie unter[2]. Auf der Clientseite sieht das etwas anders aus. Da bringt es wenig, auf das Filesystem zu loggen, da diese Logdaten auf dem Client gespeichert werden und wir in der Regel keinen Zugriff darauf haben.
Eine Möglichkeit wäre, die Logdaten an den Server zu senden und sie dort zu loggen. Der Server muss jedoch primär für das Ausführen der Businesslogik zur Verfügung stehen. Daher ist es nicht vorteilhaft, ihn mit Logaufgaben zu beschäftigen. Im ungünstigsten Fall werden so viele Logdaten von den Clients an den Server gesendet, dass dieser blockiert wird. Wir benötigen also einen alternativen Dienst, mit dem wir die Client-Log-Daten speichern können. Dieser Dienst sollte am besten günstig, hochverfügbar und von überall aus erreichbar sein. Er sollte über eine große Bandbreite verfügen und große Mengen an Daten halten können. Zudem sollte er eine einfache, offene Schnittstelle haben, damit wir ihn von verschiedenen Clienttechnologien aus verwenden können. Client-Logging beschränkt sich nämlich nicht nur auf Desktopapplikationen, auch aus Web-/JavaScript-Clients und Smartphone-Apps heraus wollen wir aufgetretene Fehler loggen können.
Die Lösung
Ein Dienst, der diese Anforderungen erfüllt, ist der Microsoft Azure Storage. Falls Sie diese Artikelserie verfolgt haben, wissen Sie: Der Azure Storage ist das Schweizer Armeemesser unter den Cloud-Diensten und ein Grundbestandteil der gesamten Azure-Infrastruktur. Er funktioniert nach dem Prinzip von Onlinespeichern wie Dropbox: Daten werden via HTTP gespeichert und gelesen. Das API des Azure Storage ist komplett RESTbasiert und kann daher von beliebigen Clienttechnologien verwendet werden.
Insbesondere ist dadurch auch der Zugriff via JavaScript und von Smartphone-Apps aus möglich. Für .NET, Java, Node.js, PHP, Ruby und Python gibt es zudem SDKs, die den REST-Zugriff in einer Library kapseln. Detaillierte Informationen zum Storage kann die Logdaten der Clients auf drei verschiedene Arten entgegennehmen: als Messages in einer Queue, als strukturierte Daten in einer nicht relationalen Tabelle oder ganze Logdateien als BLOBs.
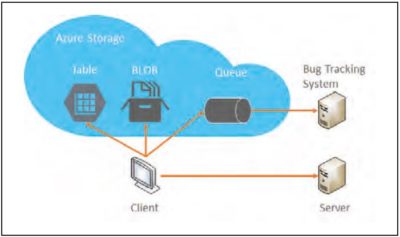
Der Einsatz einer Queue ist dann sinnvoll, wenn wir die Daten direkt weiterverarbeiten wollen. Wir können damit beispielsweise Fehlermeldungen von den Clients direkt in unser Bug-Tracking-System importieren. In meinem GitHub-Account[3] finden Sie ein Visual-Studio-Projekt, das veranschaulicht, wie Daten direkt in eine Azure Storage Queue geloggt werden können. Das Demoprojekt verwendet die log4net Library, die ich um eine eigene Queue Storage Appender-Klasse erweitert habe. Listing 1 zeigt die Methode Append des Queue- StorageAppenders, die das log4net-LoggingEvent nach JSON serialisiert und in die Cloud-Queue speichert.
Über die log4net-Konfiguration kann anhand der Log-Levels („verbose“ bis „fatal“) entschieden werden, für welche Logeinträge der QueueStorageAppender verwendet werden soll. Der Applikationscode ändert sich dadurch nicht. Wenn wir die Logdateien einfach sammeln und manuell auswerten wollen, können wir statt einer Queue den Azure BLOB Storage verwenden. Dabei speichert der Client seine Logeinträge wie gewohnt auf das lokale Dateisystem. Die Clientapplikation synchronisiert in regelmäßigen Abständen die lokalen Logdateien mit dem BLOB Storage in der Cloud. Die Logdateien können dann vom Systemverantwortlichen bei Bedarf vom BLOB Storage heruntergeladen und lokal ausgewertet werden. In der Demo-Solution finden Sie das AzureStorageFileSync-Tool, das ein lokales Logdatenverzeichnis mit einem BLOB-Container synchronisieren kann.
Eine dritte Alternative bietet der Azure Table Storage. Hier loggen wir nicht mehr in eine Datei, sondern direkt in eine nicht relationale Tabelle in der Cloud. Der Table Storage wird im Demoprojekt genauso wie der Queue Storage über einen selbst implementierten TableStorage-Appender für log4net angesprochen. Listing2 zeigt die entsprechende Append-Methode dieser Klasse. Im Beispiel wird neben der Logmeldung und dem Level auch noch die Klasse und die Zeilennummer festgehalten, um später nach diesen Attributen filtern zu können. In einer realen Umsetzung müsste man zur späteren Zuordnung einer solchen Fehlermeldung zu einem bestimmten Client auch noch eine Client-ID mitgeben.
Beurteilung der Lösung
Egal welchen der drei Ansätze man verwendet, wenn man in die Cloud loggen will, sollte man einige grundlegende Dinge beachten. Zunächst einmal kostet uns loggen immer etwas Performance. Wenn die Logdaten über das Internet gesendet werden, kann das die Geschwindigkeit der Applikation beeinflussen. Wir sollten daher clientseitig mit Bedacht loggen. Außerdem sollten wir Logeinträge buffern und asynchron senden, damit bei einer langsamen Internetverbindung der Programmfluss nicht beeinträchtigt wird.
In der Demolösung habe ich zugunsten der Übersichtlichkeit darauf verzichtet; auf meinem Blog finden Sie aber weitere Informationen dazu. Weiter sollten wir den Benutzer über das Logverhalten der Applikation informieren. Im besten Fall lassen Sie ihn selbst entscheiden, ob wir die Logdaten sammeln dürfen oder nicht. Wir müssen uns zudem bewusst sein, dass bei unseren Benutzern unter Umständen Proxy-Lösungen im Einsatz sind, die den Zugriff auf den Azure Storage erschweren.
Und schließlich gilt die goldene Regel, wenn es um Logging geht: Ins Log dürfen keine sensiblen oder sicherheitsrelevanten Informationen geschrieben werden. Variante eins, das Schreiben von Logmeldungen in eine Warteschlange, eignet sich für Szenarien, in denen wenige Logeinträge erwartet werden. Das Verfahren ist ideal für produktive Clients, bei denen selten auftretende Fehler in ein Bug-Tracking-System eingespeist oder per E-Mail versendet werden sollen. Für Szenarien mit häufigen Logeinträgen sind die beiden anderen Varianten besser geeignet, da sie die Logdaten strukturiert ablegen und dadurch statistische Auswertungen zulassen. Variante zwei, das Synchronisieren von Logdateien mit dem BLOB Storage, hat den Vorteil, dass die Logdaten in gewohnter Form gespeichert werden.
Die Auswertung der Daten kann daher mit den bestehenden Tools erfolgen. Allerdings eignet sich diese Alternative im Gegensatz zu den beiden anderen nicht für Webclients oder Smartphone-Apps. Bei diesem Ansatz muss auch beachtet werden, wie die Logdaten synchronisiert werden sollen – das macht die Implementation komplexer als bei den anderen Varianten. Variante drei, das Loggen in den Table Storage, sieht auf den ersten Blick wie die ideale Lösung aus. Der Table Storage kann einfach angesprochen werden und auch große Mengen als Logdaten strukturiert verwalten. Diese Lösung hat allerdings das Problem, dass im Gegensatz zu den anderen beiden Varianten die Logdaten für immer im Table Storage bleiben, wodurch dieser sehr schnell wachsen kann. Wir brauchen zusätzlich einen Mechanismus, der alte Logdaten wieder löscht, wenn sie nicht mehr gebraucht werden (auf Englisch „Retention Policy“ genannt). Daten im Table Storage zu löschen ist mühsam, da wir die Einträge hierzu zuerst immer holen müssen.
In der Praxis hat sich bewährt, pro Monat eine Tabelle zu machen und nach drei Monaten die jeweils älteste Tabelle ganz zu löschen. Dieses Verfahren mag für Entwickler mit SQL-Erfahrung merkwürdig scheinen, eignet sich aber gut für die nicht relationale Natur des Azure Table Storage. Auch beim Auswerten der Logdaten stößt man beim Azure Table Storage an seine Grenzen: Zum Zeitpunkt des Verfassens dieses Artikels gibt es noch keine Abfragemöglichkeiten wie Group by, Order by, Sum, Min, Max oder Average[4]. In der Praxis filtert man die Logdaten daher nach Datum, Fehlertyp oder Klassennamen und exportiert sie für die weitere Analyse. Wir verwenden dafür das kostenlose Excel-Plug-in Power Query von Microsoft, das direkt auf den Azure Table Storage zugreifen kann[5].
Kosten und Fazit
Zum Zeitpunkt des Verfassens dieses Artikels kostet der Azure BLOB Storage pro Gigabyte und Monat 0,0179 Euro. Für Queues und Tables werden 0,053 Euro pro Gigabyte und Monat berechnet. Zusätzlich werden pro 100 000 Storage-Zugriffe 0,004 Euro fällig. Ein Storage-Zugriff erfolgt bei jeder Schreib- oder Leseoperation auf einer Queue, einem BLOB oder einer Table. Weitere Details zu den Preisen finden Sie unter[6].
Der Azure Storage eignet sich sehr gut als zentraler Speicher für Clientlogdaten und bietet mit Queues, Tables und BLOB Storage verschiedene Einsatzmöglichkeiten. Zu beachten sind die Latenzzeiten gegenüber lokalen Logging-Lösungen sowie der Schutz von Benutzerdaten. Für die Auswertung der Daten müssen wir eine geeignete Strategie entwickeln, abhängig davon, welche Logvariante eingesetzt wird. Eine kostenpflichtige Alternative zum selbst implementierten Cloud-Loggen bietet z.B. Raygun.io, das von Mindscape als Software as a Service angeboten wird. Real World Azure Cloud-Dienste besitzen verschiedene sehr gute Eigenschaften. Sie sind flexibel, hochverfügbar und global erreichbar. Sie können einfach wiederverwendet und über offene Schnittstellen angesprochen werden. Das alles macht diese Dienste auch für lokale Applikationen interessant.
Dies ist der letzte Artikel meiner Real-World-Azure-Serie. Ich hoffe, ich konnte Sie davon überzeugen, dass die Dienste der Azure-Plattform Lösungen für einige gängige Probleme der Softwareentwicklung bieten. Gleichzeitig fordere ich Sie auf, selbst Ihre Erfahrungen damit zu machen und mir davon zu berichten, beispielsweise
via Twitter oder über meinem Blog.
