Taktgeber aus der Cloud
Wie können wir Azure-Dienste sinnvoll und sicher in Nicht-Cloud-Applikationen einsetzen? Wir zeigen anhand von Beispielen aus dem Projektalltag verschiedene Szenarien, in denen Cloud-Dienste eine Lösung für gängige Probleme lokaler Applikationen bieten.

Das Problem
Nachdem wir im letzten Artikel das Feld der Azure-Dienste weit geöffnet haben, fokussieren wir uns in diesem Artikel wieder auf eine einfache Problemstellung: Wie können wir zeitlich gesteuerte Abläufe implementieren, oder: Wie funktioniert Scheduling?
Scheduling kommt in der Softwareentwicklung häufig vor. Man spricht dabei von Jobs, die auf Basis eines Intervalls ausgeführt werden. Das können einfache Jobs sein wie „Überprüfe alle 30 Sekunden, ob neue Dateien in einem Verzeichnis vorhanden sind und verarbeite sie“ oder komplexere wie „Starte den Rechnungslauf der Buchhaltungssoftware jeweils am letzten Freitag des Monats um zwei Uhr morgens“. In jedem Fall ist es jedoch wichtig, dass ein Scheduling-Mechanismus zuverlässig und insbesondere ausfallsicher ist. Sollte der Scheduler nämlich versagen, bleibt das System einfach stumm. Es gibt keine Fehlermeldung und die Systemverantwortlichen merken es im schlechtesten Fall erst, wenn es bereits zu spät ist.

Coffee-as-a-Service: Kundenerlebnis neu definiert

Wachstumschancen nutzen mit der Cloud

Der Sommer trägt Blazor – und Web Components

Ein Blick hinter die bbv-Kulissen
In der .NET-Welt wird häufig entweder der Task Scheduler des Windows-Betriebssystems oder ein Scheduling-Framework verwendet. Ein beliebtes Framework ist Quartz.NET, eine Portierung aus der Java-Welt [2]. Beide Ansätze haben jedoch einen klaren Nachteil: Sie sind Single Point of Failures. Falls das System zum geplanten Zeitpunkt nicht läuft, wird der Job nicht ausgeführt, egal welchen Ansatz man implementiert hat. Ursache dafür ist möglicherweise, dass der Scheduling-Dienst nicht gestartet wurde, abgestützt ist oder dass das ganze System nicht lief, weil es aufgrund von Wartungsarbeiten heruntergefahren wurde.
Die Lösung
Es gibt verschiedene Ansätze, die Zuverlässigkeit eines Schedulers zu erhöhen. Quartz.NET kann beispielsweise die auszuführenden Jobs persistieren und behält so den Überblick darüber, welche Jobs noch ausgeführt werden müssen und welche bereits ausgeführt wurden. Eine einfachere und tendenziell zuverlässigere Alternative bietet jedoch die Cloud. Der Microsoft Azure Scheduler Service bietet die Möglichkeit, zeitlich gesteuerte Jobs in der Cloud zu erstellen. Diese Jobs werden vom Azure Scheduler verwaltet und je nach Intervall wird zum definierten Zeitpunkt entweder ein HTTP-Aufruf ausgeführt oder eine Nachricht in eine Warteschlange (Queue) geschrieben (Abb. 1).
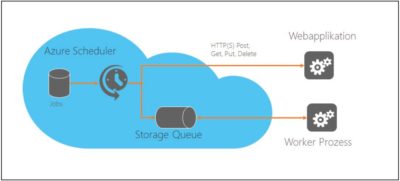
Abb. 1: Queue unter Azure Scheduler.
Der Azure Scheduler kann HTTP- oder Storage-Queue-Jobs ausführen
Es stehen die HTTP-Methoden GET, PUT, POST und DELETE zur Verfügung, und als Warteschlange können die Azure Storage Queues verwendet werden. Azure Service Bus Messaging wird zum Verfassungszeitpunkt dieses Artikels noch nicht vom Azure Scheduler unterstützt. An welches System dieser Aufruf geht und Art sowie Inhalt der Nachricht kann der Benutzer vollkommen selbst bestimmen, der Azure Scheduler reichert die Nachricht lediglich noch mit gewissen Metadaten an, z. B. mit einer eindeutigen Laufnummer. Wieso aber hat der Azure Scheduler eine höhere Verfügbarkeit und Zuverlässigkeit als eine lokale Implementation?
Zunächst einmal ist der Azure Scheduler eine zentrale Komponente innerhalb des Azure- Ökosystems. Viele andere Azure-Dienste wie SQL Azure Databases Backup, Azure Websites Web Jobs oder Azure Mobile Services lagern das Scheduling an den Scheduler aus. Der Azure Scheduler ist georedundant deployt und läuft in allen Azure-Datencentern parallel. Auch alle Jobs werden zwischen den Datencentern repliziert. Kommt es also um Ausfall in einem der Datencenter, werden die Jobs von einem anderen aus ausgeführt.
Dabei kann es sich von einer einfachen Netzwerkstörung bis hin zum kompletten Ausfall eines Datencenters aufgrund von Naturkatastrophen um alles handeln. Um eine annähernd vergleichbare Ausfallsicherheit gewährleisten zu können, müssten selbst große Unternehmen sehr viel Geld in ihre IT-Infrastruktur investieren. Für KMUs ist das finanziell nicht denkbar.
Daneben bietet der Azure Scheduler zusätzlich ein konfigurierbares Fehlerhandling an. Es ist möglich, mittels einer Retry Policy zu bestimmen, wann und wie oft ein HTTP-Request im Fehlerfall wiederholt werden soll. Weiter kann ein alternativer Endpoint angegeben werden, falls das primäre Ziel auch nach wiederholten Versuchen nicht erreichbar ist. Und schließlich führt der Azure Scheduler über jeden Job genau Buch, was es dem Benutzer ermöglicht, jederzeit zu überprüfen, welche Jobs wann ausgeführt wurden und ob sie erfolgreich waren. Detailliertere Informationen zum Azure-Scheduler-Dienst finden Sie auf meinem Blog [1].
Beurteilung
Zeitgesteuerte Jobs sind häufig Batchverarbeitungsprogramme, die über längere Zeit laufen und bestimmte Aufgaben abarbeiten. Solche Programme laufen als Dienst, Skript oder Konsolenapplikation auf einem geschützten Server und können in der Regel nicht von außen via HTTP aufgerufen werden. Insofern ist die HTTP-Funktionalität des Azure Schedulers zwar spannend für Webapplikationen, die Variante, zeitgesteuert Nachrichten in eine Message-Queue zu stellen, bietet aber sehr viel mehr Einsatzmöglichkeiten.
So können wir einen Worker-Prozess implementieren, der die Message-Queue regelmäßig nach neuen Nachrichten abfragt. Wenn nach dem Ablauf des Intervalls eine solche Nachricht vom Scheduler in die Queue gestellt worden ist, wird sie abgeholt und ein bestimmter Job ausgeführt. Die Zeitsteuerung ist komplett in die Cloud ausgelagert und das Abfragen der Warteschlange kann mithilfe des Azure Storage SDKs sehr einfach implementiert werden.
Entkoppelung und Verfügbarkeit
Die Verwendung einer Warteschlange zwischen Scheduler und Worker-Prozess hat weitere Vorteile: Sie bietet zunächst eine sehr schöne Entkoppelung der Verantwortlichkeiten. Will man den Prozess nicht zeitgesteuert, sondern manuell auslösen, braucht man lediglich eine Nachricht in die Warteschlange zu stellen. Ist der Worker-Prozess online, verarbeitet er die Nachricht zeitnah. Wird das System aber beispielsweise gerade neu gebootet, bleibt die Nachricht einfach so lange in der Warteschlange, bis sie abgeholt und verarbeitet wird.
Der Prozess ist also unabhängig vom Aufrufer, sowohl technisch bezüglich der Schnittstelle als auch zeitlich, da der Aufruf nicht mehr synchron erfolgen muss. Weiterhin können wir durch den Einsatz der Warteschlange auch die Verfügbarkeit unseres Systems erhöhen, indem wir mehrere Instanzen unseres Prozesses auf unterschiedlichen Servern installieren. Fällt einer der Prozesse aus, holt ein anderer die Nachricht aus der Queue ab und verarbeitet sie. Das Gesamtsystem bleibt immer verfügbar, solange einer der installierten Prozesse online ist.
Skalierbarkeit
Schließlich können wir mit dem Azure Scheduler auch die Skalierbarkeit unseres Systems erhöhen. Um Ihnen das zu zeigen, verwende ich ein Beispiel aus der Praxis: Auf einem FTP-Server werden von verschiedenen Quellen Dateien abgelegt. Wir erhalten die Aufgabe, einen Prozess zu implementieren, der regelmäßig auf dem FTP-Server prüft, ob neue Dateien vorhanden sind, diese verarbeitet und löscht. Wir wissen jedoch, dass pro Minute mehr Dateien produziert werden, als wir mit einer Instanz unseres Prozesses verarbeiten können. Wir errechnen, dass wir mit drei parallelen Instanzen auf der sicheren Seite sind. Wie teilen wir die Dateien auf dem FTP-Server auf diese drei Instanzen auf? Wie machen wir diesen Prozess skalierbar?
Wenn wir die drei Instanzen einfach laufen lassen, werden die Dateien dreifach verarbeitet, weil die eine Instanz nicht weiß, was die anderen beiden machen und alle Instanzen alle Dateien verarbeiten wollen. Wir könnten die Dateien auf dem FTP-Server in Ordner ablegen und jeder Instanz fix bestimmte Ordner zuweisen. Damit sind wir zwar skalierbar, haben aber die Verfügbarkeit des Systems beeinträchtigt, da eine Instanz nur die ihr zugewiesenen Dateien verarbeitet, nicht aber die Arbeit einer anderen übernehmen kann, falls diese ausfällt.
Wenn wir den Azure Scheduler wie oben beschrieben mit der Queue implementieren, haben wir den umgekehrten Fall: Wir erhöhen zwar die Verfügbarkeit, da aber immer nur eine der drei Instanzen arbeitet, – nämlich diejenige, die die Nachricht aus der Queue geholt hat – ist unsere Applikation nicht skalierbar. Eine Lösung für dieses Dilemma sieht folgendermaßen aus: Wir trennen das Prüfen auf neue Dateien von der Verarbeitung. Der Azure Scheduler liefert uns regelmäßig eine Nachricht in eine erste Queue (Abb. 2).
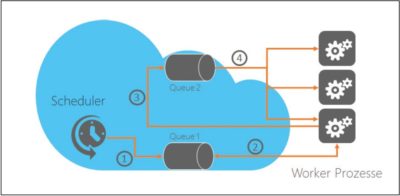
Abb. 2: Um die Datenverarbeitung skalierbar und ausfallsicher zu machen, benötigen wir zwei Queues.
Einer unserer Prozesse holt die Nachricht ab und prüft, welche Dateien auf dem FTP-Server verfügbar sind. Für jede Datei, die verarbeitet werden muss, erstellt er je eine Nachricht und stellt diese in eine weitere Queue. Die Nachricht beinhaltet den Dateinamen der zu verarbeitenden Datei. Die zweite Queue beinhaltet jetzt für jede zu verarbeitende Datei eine Nachricht und diese Nachrichten können von allen Prozessen parallel verarbeitet werden. Der Einsatz der Queue stellt sicher, dass keine Datei doppelt verarbeitet wird. Unsere Implementation ist jetzt hochskalierbar und ausfallsicher. Wir können beliebig viele weitere Instanzen unseres Prozesses hinzufügen oderauch zur Laufzeit entfernen. Auf windowsdeveloper.de und in meinem GitHub-Account finden Sie eine Visual Studio Solution, die eine solche Lösung im Ansatz demonstriert [3].
In gewissen Fällen kann es trotzdem noch zu doppelten Verarbeitungen der Dateien kommen. Dann nämlich, wenn unsere Instanzen innerhalb des zeitlichen Intervalls nicht mit der Datenverarbeitung nachkommen und bereits wieder Dateien indexiert werden. Solche Fälle von Duplikationen müssen wir innerhalb der Applikationslogik erkennen und abfangen. Man nennt das auch eine idempotente Verarbeitung der Daten.
Kosten
Den Azure Scheduler gibt es in einer Gratis-, Standard und Premiumausführung. Die kostenlose Variante ist beschränkt auf ein minimales Intervall von einer Stunde, maximal fünf Jobs und maximal 3 600 Jobausführungen pro Monat. Für knapp 15 Euro pro Monat erhält man den Standardaccount mit insgesamt 500 Jobs, einem minimalen Intervall von einer Minute und einer uneingeschränkten Anzahl an Jobausführungen. Beim Premiumaccount können für knapp 150 Euro pro Monat insgesamt 500 000 Jobs erstellt werden. Die detaillierten Kosten für Azure Scheduler und Azure Storage Queue finden Sie unter [4].
Fazit
Der Azure Scheduler Service besticht durch seine Ausfallsicherheit, seine Konfigurierbarkeit, das Monitoring und den einfachen, aber vielseitigen Einsatz. Dank der Möglichkeit, zeitgesteuert Nachrichten in eine Message-Queue zu schreiben, können Scheduler und Worker-Prozess sauber voneinander entkoppelt und die Verfügbarkeit sowie Skalierbarkeit des Systems weiter erhöht werden. Im nächsten Teil der Serie wird es darum gehen, wie wir Log-Daten von Clients in der Cloud sammeln und auswerten können.
Links & Literatur
[1] http://rolandkru.azurewebsites.net/rwwa
[2] http://www.quartz-scheduler.net
[3] https://github.com/rolandkru/RWWA-Article4
[4] http://azure.microsoft.com/de-De/pricing/overview
